Transformer 架构:从零开始理解每一步
本文用一张架构图把 Transformer 的每一步拆开讲清楚,适合没有深度学习基础的读者。
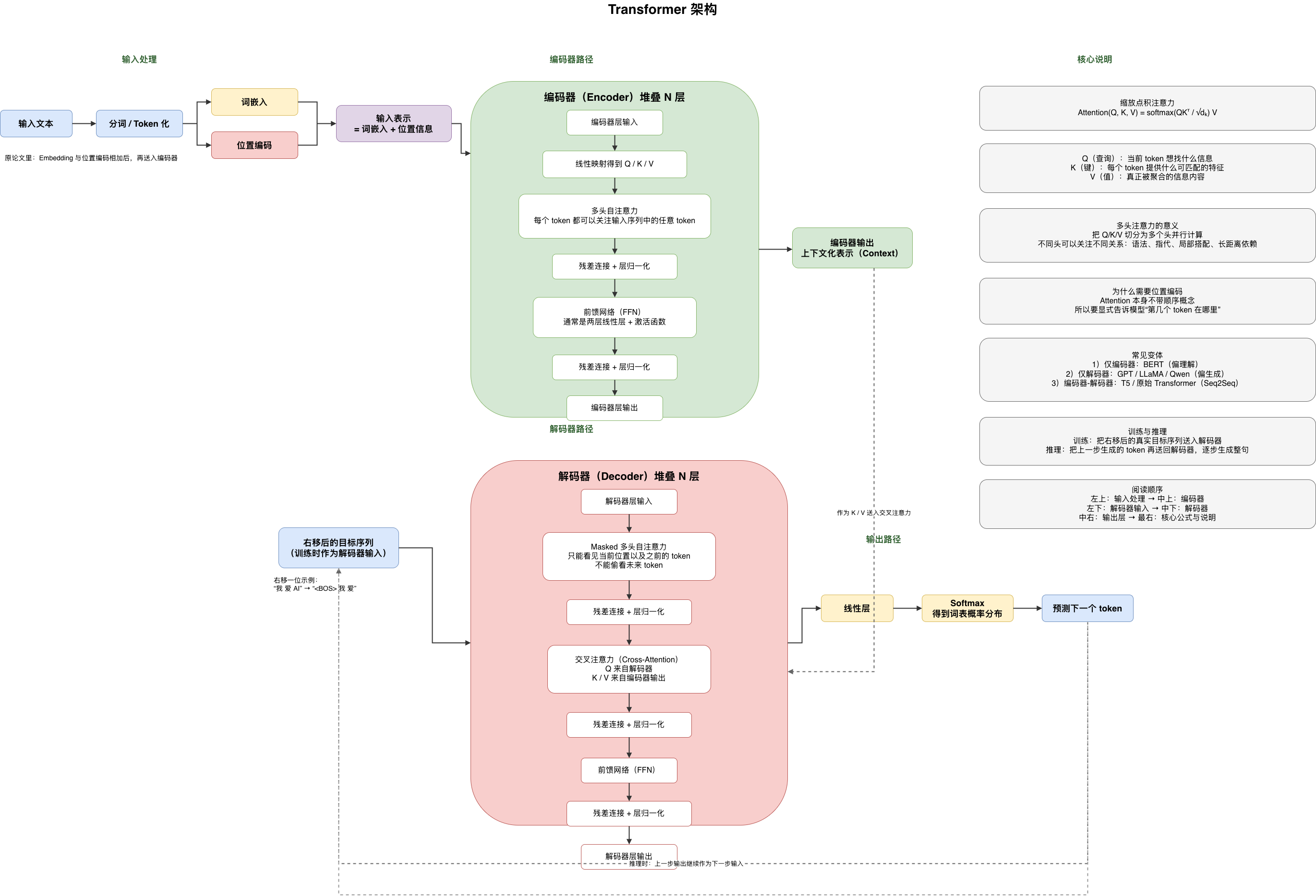
一、全局视角:Transformer 在做什么
一句话:把一段输入序列变成一段输出序列。
翻译任务举例:输入「I love you」→ 输出「我爱你」。Transformer 通过 编码器(Encoder) 理解输入,再通过 解码器(Decoder) 逐步生成输出。
整个流程可以拆成四大块:
| 阶段 | 做什么 | 对应图中位置 |
|---|---|---|
| 输入处理 | 文本 → 数字向量 | 左侧绿色区域 |
| 编码器 | 理解输入的完整语义 | 上方红色框 |
| 解码器 | 逐个生成输出 token | 下方粉色框 |
| 输出预测 | 向量 → 概率 → 选词 | 右下角黄/蓝色框 |
二、输入处理:让机器「读懂」文字
2.1 分词 / Token 化
机器不认识汉字和单词,需要先把文本切成最小单元——token。
"I love you" → ["I", "love", "you"]
"我爱你" → ["我", "爱", "你"]
每个 token 对应词表里的一个编号(整数),比如 love → 3421。
2.2 词嵌入(Embedding)
一个整数编号信息量太少。词嵌入把每个编号映射成一个高维向量(比如 512 维的浮点数组),让语义相近的词在向量空间里距离更近。
"love" → [0.12, -0.34, 0.56, ...] (512 个数)
"like" → [0.11, -0.31, 0.55, ...] ← 和 love 很接近
"car" → [-0.78, 0.22, 0.01, ...] ← 和 love 差很远
这个映射表是模型训练出来的,不是人工设定的。
2.3 位置编码(Positional Encoding)
为什么需要? Transformer 不像 RNN 那样逐个读入单词,它是一次性看到所有 token 的。这意味着它天生分不清「狗咬人」和「人咬狗」——词是一样的,只是顺序不同。
位置编码给每个位置生成一个独特的向量,和词嵌入相加,让模型知道谁在前、谁在后。
输入表示 = 词嵌入 + 位置编码
补充: 原始论文用 sin/cos 函数生成固定位置编码;后来的模型(如 RoPE)改用了更灵活的旋转位置编码。
处理完毕后,每个 token 变成了一个既包含语义、又包含位置的向量,这组向量就是编码器的输入。
三、编码器(Encoder):理解输入
编码器堆叠 N 层(原始论文 N=6),每层结构完全相同,包含两个子模块:多头自注意力 和 前馈网络。
3.1 线性投影到 Q / K / V
进入注意力之前,先把每个 token 的向量用三个不同的线性变换,分别投影成三个新向量:
| 向量 | 全称 | 直觉含义 |
|---|---|---|
| Q(Query,查询) | 「我想找什么信息?」 | 当前 token 发出的搜索请求 |
| K(Key,键) | 「我能提供什么信息?」 | 每个 token 公开的标签 |
| V(Value,值) | 「我的实际内容是什么」 | 真正会被取走的信息 |
为什么要分成三个?如果 Q 和 K 直接用同一个向量,模型只能做「我和你像不像」的比较;分开后可以实现「我想找的」和「你能提供的」是不同维度的匹配,表达能力更强。
3.2 多头自注意力(Multi-Head Self-Attention)
核心公式:
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right) V\]拆解步骤:
- 打分: 用 Q 和所有 K 做点积 → 得到每对 token 之间的”相关度分数”
- 缩放: 除以 \(\sqrt{d_k}\)(向量维度的平方根),防止分数过大导致 softmax 梯度消失
- 归一化: softmax 把分数变成 0~1 之间的权重,所有权重加起来等于 1
- 加权求和: 用权重对 V 做加权求和 → 每个 token 得到了一个融合了其他 token 信息的新向量
自注意力的意义: 每个 token 可以”关注”输入中所有位置的其他 token。比如在「The cat sat on the mat because it was tired」中,自注意力让 “it” 知道自己指的是 “cat” 而不是 “mat”。
为什么是”多头”? 把 Q/K/V 分成多组(比如 8 组),每组独立计算注意力,最后拼接。不同的”头”可以关注不同方面:
- 某个头关注语法结构(主谓宾)
- 某个头关注指代关系(it → cat)
- 某个头关注相邻词的搭配
- 某个头关注长距离依赖
3.3 残差连接 + 层归一化
输出 = LayerNorm(x + SubLayer(x))
- 残差连接(x + …): 把子层的输入直接加到输出上。好处是让梯度能”走捷径”传回去,避免深层网络训练困难。
- 层归一化(LayerNorm): 把每个向量的数值范围拉回稳定区间,加速训练收敛。
每个子模块(注意力、FFN)之后都有这一对操作,图中共出现 2 次。
3.4 前馈网络(FFN)
FFN(x) = W₂ · GELU(W₁ · x + b₁) + b₂
两个线性层夹一个激活函数(GELU)。可以理解为:注意力负责”在 token 之间交换信息”,FFN 负责”对每个 token 自己的信息做深加工”。
通常 FFN 的中间维度是输入的 4 倍(比如 512 → 2048 → 512),让模型有更大的”思考空间”。
3.5 编码器输出
经过 N 层堆叠后,输出的向量组称为上下文化表示(Context)。每个 token 的向量现在不再只代表自己,而是融合了整段输入的完整语义。这组向量会被送到解码器使用。
四、解码器(Decoder):逐步生成输出
解码器同样堆叠 N 层,但比编码器多一个子模块(交叉注意力),共三个子模块。
4.1 右移的目标序列
解码器的输入是已经生成的部分结果(推理时)或右移的正确答案(训练时)。
正确答案: "我" "爱" "你" "<EOS>"
右移后: "<BOS>" "我" "爱" "你"
这样,每个位置的任务就是根据左边已有的内容,预测下一个 token。
4.2 Masked 多头自注意力
和编码器的自注意力几乎一样,区别在于加了遮罩(Mask):每个 token 只能看到自己和左边的 token,看不到右边(未来的 token)。
为什么要遮罩?因为生成是从左到右的,生成第 3 个词时,第 4 个词还不存在。训练时虽然能看到完整答案,但必须用 mask 模拟这种”看不到未来”的真实推理场景,否则模型会”作弊”。
4.3 交叉注意力(Cross-Attention)
这是解码器独有的模块:
- Q 来自解码器(当前正在生成的 token)
- K 和 V 来自编码器输出(输入句子的完整语义)
作用:让解码器在生成每个词时,能够”回头看”输入句子。比如翻译「I love you」时,生成「爱」这个字需要关注输入中的「love」。
4.4 FFN + 残差连接 + 层归一化
和编码器完全一样,不再赘述。每个子模块之后都有残差连接和层归一化。
4.5 解码器层的堆叠
解码器同样堆叠 N 层,上一层的输出作为下一层的输入,逐层精炼。
五、输出预测:从向量到文字
解码器最后一层的输出是一组向量,还需要转回文字:
- 线性层: 把向量映射到词表大小的维度(比如 50000 维,对应词表中每个词一个分数)
- Softmax: 把分数转成概率分布(所有词的概率之和 = 1)
- 选词: 取概率最高的那个 token 作为输出(贪心策略),或用 beam search / 采样等策略
然后把这个新 token 拼到解码器输入的末尾,重复整个解码过程,直到生成 <EOS>(结束符)。
六、训练 vs 推理的区别
| 训练 | 推理 | |
|---|---|---|
| 编码器 | 运行一次 | 运行一次 |
| 解码器输入 | 右移后的完整正确答案(Teacher Forcing) | 已生成的部分序列,逐步增长 |
| 解码器运行 | 一次并行处理所有位置(靠 mask 防作弊) | 一步步循环,每步多生成一个 token |
| 目标 | 缩小预测和正确答案的差距,更新参数 | 用训练好的参数直接生成 |
Teacher Forcing(教师强制): 训练时不等模型自己生成上一个词再喂下一个,而是直接把正确答案喂给解码器。这样训练更稳定、收敛更快。
七、主要变体
原始 Transformer 是 Encoder-Decoder 结构,后来衍生出三大家族:
| 变体 | 结构 | 代表模型 | 擅长 |
|---|---|---|---|
| 仅编码器 | 只用 Encoder | BERT | 理解型任务(分类、抽取、问答) |
| 仅解码器 | 只用 Decoder | GPT、LLaMA、Qwen | 生成型任务(对话、写作、代码) |
| 编码器-解码器 | 完整结构 | T5、原始 Transformer | 序列到序列(翻译、摘要) |
现在最流行的大语言模型(ChatGPT、Claude、Qwen 等)大多是仅解码器架构——去掉了编码器和交叉注意力,只保留带 mask 的自注意力和 FFN,靠超大规模数据和参数量实现强大的生成能力。
八、总结:一张图的完整信息流
输入文本
↓ 分词 / Token 化
↓ 词嵌入 + 位置编码
↓
┌─────────── 编码器 × N 层 ──────────┐
│ 线性投影 → Q / K / V │
│ 多头自注意力(看所有位置) │
│ 残差连接 + 层归一化 │
│ 前馈网络(FFN) │
│ 残差连接 + 层归一化 │
└───────────────────────────────────┘
↓ 上下文化表示(Context)
↓ K, V 传入解码器的交叉注意力
┌─────────── 解码器 × N 层 ──────────┐
│ Masked 多头自注意力(只看左边) │
│ 残差连接 + 层归一化 │
│ 交叉注意力(Q 来自解码器,KV 来自编码器)│
│ 残差连接 + 层归一化 │
│ 前馈网络(FFN) │
│ 残差连接 + 层归一化 │
└───────────────────────────────────┘
↓
线性层 → Softmax → 预测下一个 token
参考
- Vaswani et al., Attention Is All You Need, 2017
- Jay Alammar, The Illustrated Transformer
 支付宝打赏
支付宝打赏  微信打赏
微信打赏